前置准备
x和y数据集数量调整
1 | #1.2.1构建输入的X数据,随机数返回64*2的矩阵,表示64组x1和x2的特征,作为输入数据集 |
多种生成方法
三种反向传播方法
1 | #定义损失函数和反向传播方法 |
(实验rate用了0.001,以0.001为准;为达到控制变量法的目的,除了指明的改变,其他数值都没有动过)
我的推测:rate更大,达到最后的精度也越快,但loss(可能)会较rate小的更大
但实际上我遇到了0.01比0.001更精确的情况。
所以推测!=实际;
实验结果对推测补充:
在有限步长内,rate大的是有可能在最后的精度比rate小的要更精确一些的。
问了一下读人工智能相关专业的朋友,这个原因可能是因为我用的反向传播方法是梯度下降,说是clipping大的话,rate大确实可能更准。
参数生成
1 | # #正态分布 |
因为是入坑实验,所以隐藏层并不多。
测试记录
正态分布随机数 搭配 梯度下降方法
稳定趋势
图像没有记录第500次,从1000开始记录,大概5000左右稳定;
大概28000次趋于稳定值0.022411(详情可见附录)。
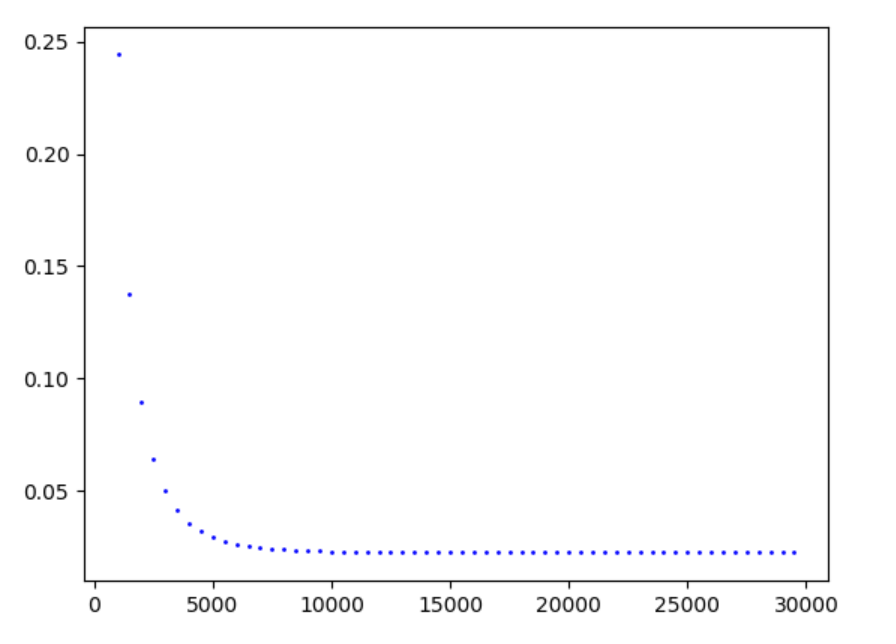
从1000开始记录
注:主要还是500步采样一次
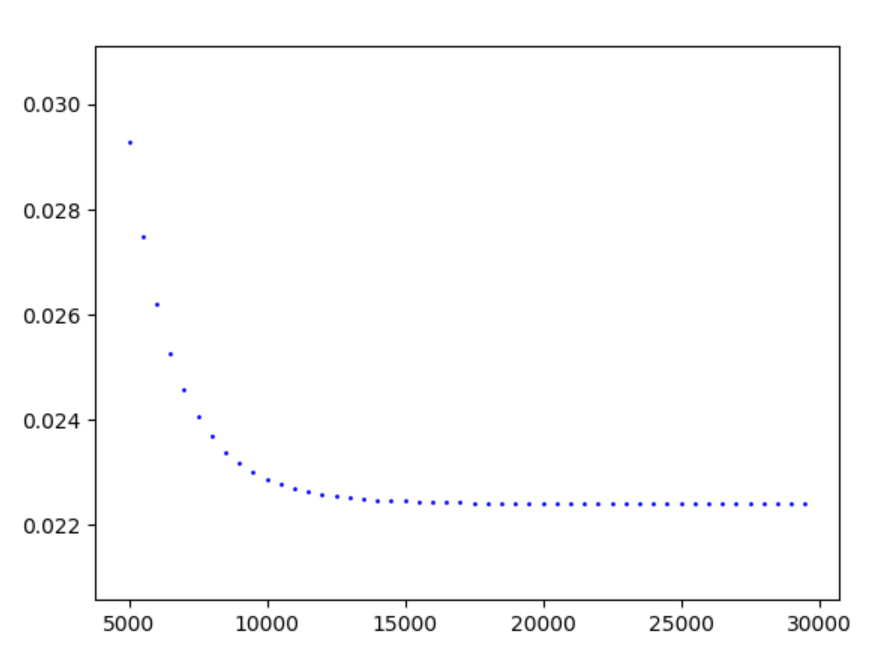
从5000开始记录
注:主要还是500步采样一次
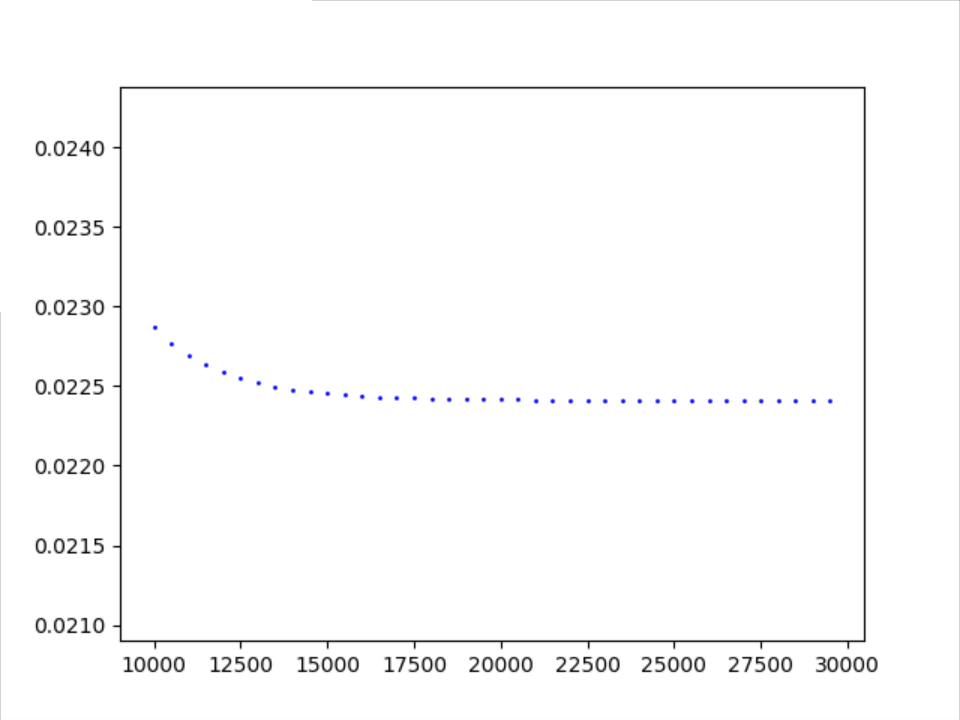
15000开始记录,差距已经很小了
最终数集
w1:
[[-0.09965871 0.43331614 -0.30294925 -0.67511696 0.0145967 ]
[ 0.6045473 0.55147547 -2.1025834 -0.65748686 -0.05805822]]
w2:
[[-0.1577921 ]
[ 0.37533042]
[-0.09460549]
[-0.60455596]
[ 0.02013253]]
正态分布随机数 搭配 adam优化器
稳定趋势
大概4000次趋于稳定值0.0224109(详情可见附录)。
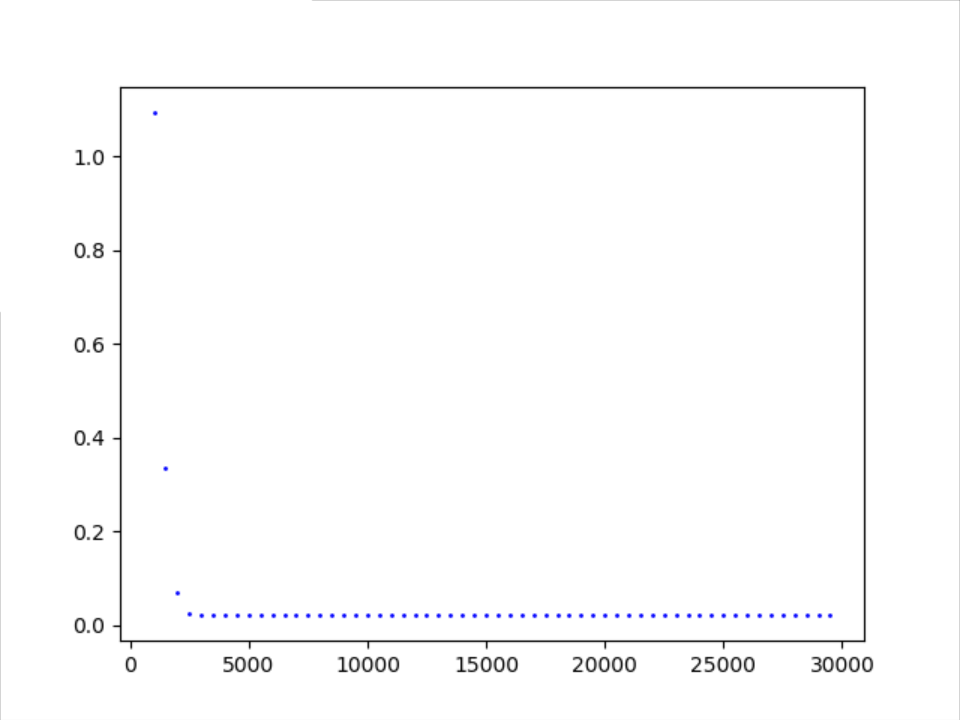
从1000开始记录
注:主要还是500步采样一次
从5000开始记录
注:主要还是500步采样一次
从15000开始记录
注:主要还是500步采样一次
最终数集
w1:
[[-0.3398727 0.7914813 -1.2407142 -1.7048413 -1.5274317 ]
[ 0.9581162 0.40073904 -2.2300196 -0.5427008 0.07002888]]
w2:
[[ 0.4388571 ]
[ 0.9039359 ]
[ 0.51874536]
[-1.7928427 ]
[ 1.5478728 ]]
正态分布随机数 搭配 momentum优化器
稳定趋势
大概2500次趋于稳定值0.0224109(详情可见附录)。
从1000开始记录
注:主要还是500步采样一次
从5000开始记录
注:主要还是500步采样一次
从15000开始记录
注:主要还是500步采样一次
最终数集
w1:
[[-0.24079864 0.49667582 -0.05004572 -0.8087648 0.0299942 ]
[ 0.65848863 0.38528863 -2.023655 -0.39416346 -0.06530844]]
w2:
[[-0.08400149]
[ 0.33123904]
[-0.2132142 ]
[-0.51825726]
[ 0.01197585]]
去掉偏离过大的正态分布 搭配 momentum优化器
稳定趋势
可能是我数据选的巧,这两行log很惊艳。
After 0 training step(s),loss_mse on all data is1.20265
After 500 training step(s),loss_mse on all data is0.0232303
大概2000次趋于稳定值0.0224109(详情可见附录)。
从1000开始记录
注:主要还是500步采样一次
从5000开始记录
注:主要还是500步采样一次
从15000开始记录
注:主要还是500步采样一次
最终数集
w1:
[[-0.4259683 0.6639827 0.08575324 -0.00566949 0.26860955]
[ 1.5576472 0.2803266 -1.5200454 1.3749744 0.59499794]]
w2:
[[-0.16364342]
[ 0.6981152 ]
[-0.16441868]
[ 0.21937802]
[ 0.36119953]]
从均匀分布[0,1)中采样 搭配 momentum优化器
稳定趋势
数据大概4000趋于稳定值0.0224109(详情可见附录)。
注:
#从均匀分布[0,1)中采样
w1 = tf.Variable(tf.random_uniform([2,5],minval=0,maxval=1,dtype=tf.float32,seed=1))
w2 = tf.Variable(tf.random_uniform([5,1],minval=0,maxval=1,dtype=tf.float32,seed=1))
#这里改成了float32才能正确运行 具体代码以上交的作业为准 截图有些地方有更改
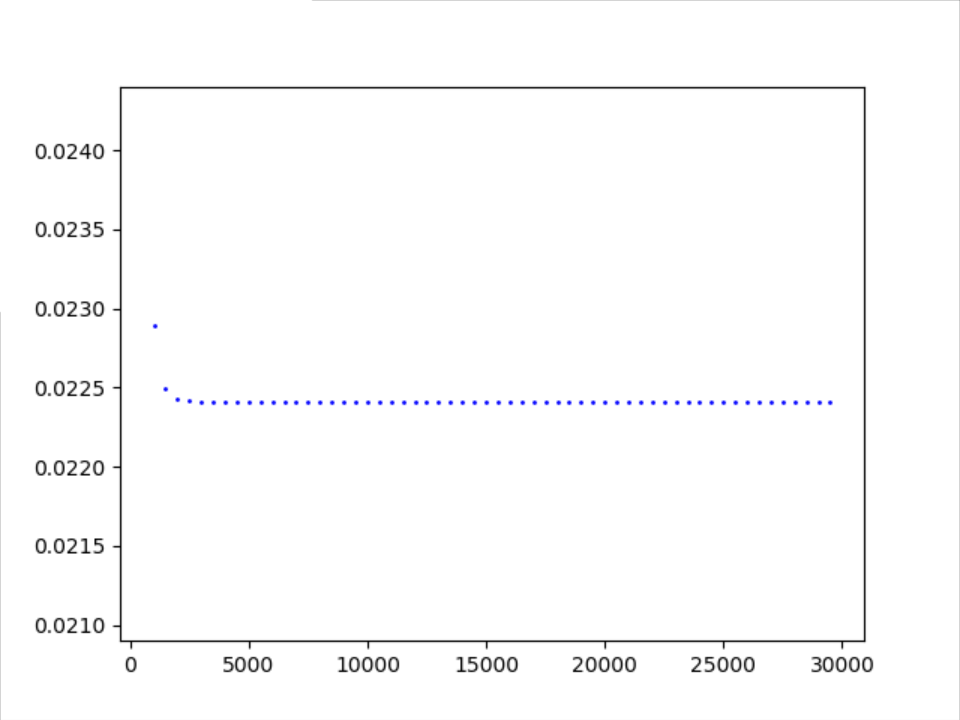
从1000开始记录
注:主要还是500步采样一次
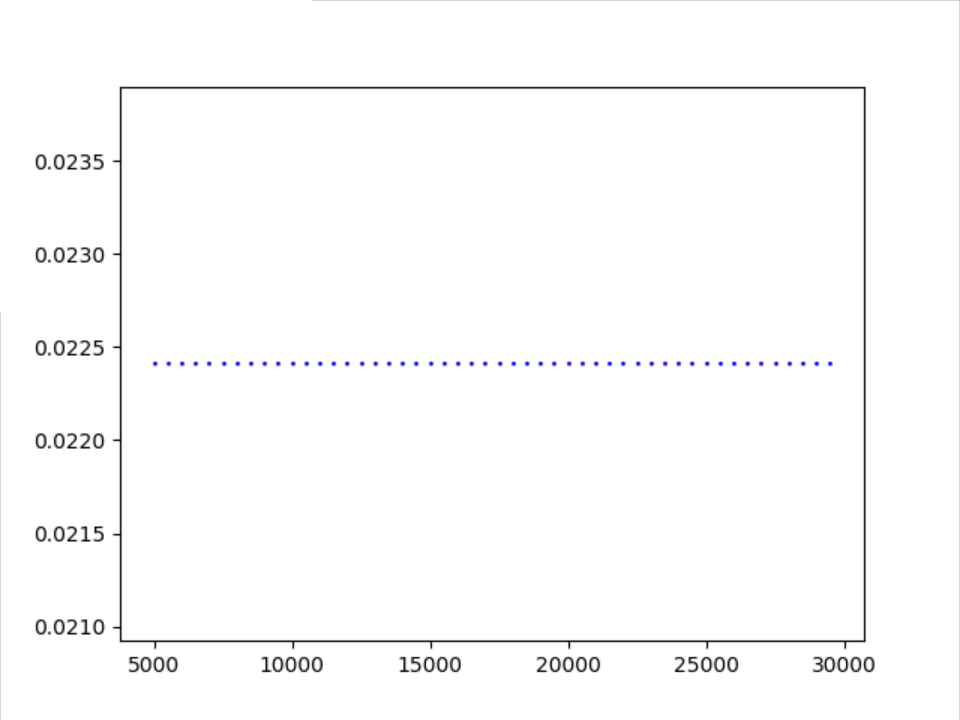
从5000开始记录
注:主要还是500步采样一次
从15000开始记录
注:主要还是500步采样一次
最终数集
w1:
[[0.13173957 0.50678813 0.04327347 0.2976472 0.48253357]
[0.02846832 0.0958555 0.45540482 0.77031714 0.74220717]]
w2:
[[0.130316 ]
[0.5006925 ]
[0.06292133]
[0.3262457 ]
[0.50605714]]
附录:数据
正态分布随机数 搭配 梯度下降方法
After 0 training step(s),loss_mse on all data is24.0595
After 500 training step(s),loss_mse on all data is0.550114
After 1000 training step(s),loss_mse on all data is0.24429
After 1500 training step(s),loss_mse on all data is0.137479
After 2000 training step(s),loss_mse on all data is0.0893748
After 2500 training step(s),loss_mse on all data is0.0643284
After 3000 training step(s),loss_mse on all data is0.049995
After 3500 training step(s),loss_mse on all data is0.0412315
After 4000 training step(s),loss_mse on all data is0.0356065
After 4500 training step(s),loss_mse on all data is0.03186
After 5000 training step(s),loss_mse on all data is0.0292913
After 5500 training step(s),loss_mse on all data is0.027489
After 6000 training step(s),loss_mse on all data is0.0262005
After 6500 training step(s),loss_mse on all data is0.025265
After 7000 training step(s),loss_mse on all data is0.024577
After 7500 training step(s),loss_mse on all data is0.0240656
After 8000 training step(s),loss_mse on all data is0.0236819
After 8500 training step(s),loss_mse on all data is0.0233918
After 9000 training step(s),loss_mse on all data is0.023171
After 9500 training step(s),loss_mse on all data is0.0230019
After 10000 training step(s),loss_mse on all data is0.0228719
After 10500 training step(s),loss_mse on all data is0.0227715
After 11000 training step(s),loss_mse on all data is0.0226935
After 11500 training step(s),loss_mse on all data is0.0226329
After 12000 training step(s),loss_mse on all data is0.0225856
After 12500 training step(s),loss_mse on all data is0.0225486
After 13000 training step(s),loss_mse on all data is0.0225196
After 13500 training step(s),loss_mse on all data is0.0224968
After 14000 training step(s),loss_mse on all data is0.0224788
After 14500 training step(s),loss_mse on all data is0.0224647
After 15000 training step(s),loss_mse on all data is0.0224535
After 15500 training step(s),loss_mse on all data is0.0224447
After 16000 training step(s),loss_mse on all data is0.0224377
After 16500 training step(s),loss_mse on all data is0.0224322
After 17000 training step(s),loss_mse on all data is0.0224278
After 17500 training step(s),loss_mse on all data is0.0224244
After 18000 training step(s),loss_mse on all data is0.0224216
After 18500 training step(s),loss_mse on all data is0.0224194
After 19000 training step(s),loss_mse on all data is0.0224177
After 19500 training step(s),loss_mse on all data is0.0224163
After 20000 training step(s),loss_mse on all data is0.0224152
After 20500 training step(s),loss_mse on all data is0.0224143
After 21000 training step(s),loss_mse on all data is0.0224136
After 21500 training step(s),loss_mse on all data is0.0224131
After 22000 training step(s),loss_mse on all data is0.0224126
After 22500 training step(s),loss_mse on all data is0.0224123
After 23000 training step(s),loss_mse on all data is0.022412
After 23500 training step(s),loss_mse on all data is0.0224118
After 24000 training step(s),loss_mse on all data is0.0224116
After 24500 training step(s),loss_mse on all data is0.0224115
After 25000 training step(s),loss_mse on all data is0.0224114
After 25500 training step(s),loss_mse on all data is0.0224113
After 26000 training step(s),loss_mse on all data is0.0224112
After 26500 training step(s),loss_mse on all data is0.0224111
After 27000 training step(s),loss_mse on all data is0.0224111
After 27500 training step(s),loss_mse on all data is0.0224111
After 28000 training step(s),loss_mse on all data is0.022411
After 28500 training step(s),loss_mse on all data is0.022411
After 29000 training step(s),loss_mse on all data is0.022411
After 29500 training step(s),loss_mse on all data is0.022411
正态分布随机数 搭配 momentum优化器
After 0 training step(s),loss_mse on all data is24.0595
After 500 training step(s),loss_mse on all data is0.0250445
After 1000 training step(s),loss_mse on all data is0.0224777
After 1500 training step(s),loss_mse on all data is0.0224129
After 2000 training step(s),loss_mse on all data is0.022411
After 2500 training step(s),loss_mse on all data is0.0224109
After 3000 training step(s),loss_mse on all data is0.0224109
After 3500 training step(s),loss_mse on all data is0.0224109
After 4000 training step(s),loss_mse on all data is0.0224109
After 4500 training step(s),loss_mse on all data is0.0224109
After 5000 training step(s),loss_mse on all data is0.0224109
After 5500 training step(s),loss_mse on all data is0.0224109
After 6000 training step(s),loss_mse on all data is0.0224109
After 6500 training step(s),loss_mse on all data is0.0224109
After 7000 training step(s),loss_mse on all data is0.0224109
After 7500 training step(s),loss_mse on all data is0.0224109
After 8000 training step(s),loss_mse on all data is0.0224109
After 8500 training step(s),loss_mse on all data is0.0224109
After 9000 training step(s),loss_mse on all data is0.0224109
After 9500 training step(s),loss_mse on all data is0.0224109
After 10000 training step(s),loss_mse on all data is0.0224109
After 10500 training step(s),loss_mse on all data is0.0224109
After 11000 training step(s),loss_mse on all data is0.0224109
After 11500 training step(s),loss_mse on all data is0.0224109
After 12000 training step(s),loss_mse on all data is0.0224109
After 12500 training step(s),loss_mse on all data is0.0224109
After 13000 training step(s),loss_mse on all data is0.0224109
After 13500 training step(s),loss_mse on all data is0.0224109
After 14000 training step(s),loss_mse on all data is0.0224109
After 14500 training step(s),loss_mse on all data is0.0224109
After 15000 training step(s),loss_mse on all data is0.0224109
After 15500 training step(s),loss_mse on all data is0.0224109
After 16000 training step(s),loss_mse on all data is0.0224109
After 16500 training step(s),loss_mse on all data is0.0224109
After 17000 training step(s),loss_mse on all data is0.0224109
After 17500 training step(s),loss_mse on all data is0.0224109
After 18000 training step(s),loss_mse on all data is0.0224109
After 18500 training step(s),loss_mse on all data is0.0224109
After 19000 training step(s),loss_mse on all data is0.0224109
After 19500 training step(s),loss_mse on all data is0.0224109
After 20000 training step(s),loss_mse on all data is0.0224109
After 20500 training step(s),loss_mse on all data is0.0224109
After 21000 training step(s),loss_mse on all data is0.0224109
After 21500 training step(s),loss_mse on all data is0.0224109
After 22000 training step(s),loss_mse on all data is0.0224109
After 22500 training step(s),loss_mse on all data is0.0224109
After 23000 training step(s),loss_mse on all data is0.0224109
After 23500 training step(s),loss_mse on all data is0.0224109
After 24000 training step(s),loss_mse on all data is0.0224109
After 24500 training step(s),loss_mse on all data is0.0224109
After 25000 training step(s),loss_mse on all data is0.0224109
After 25500 training step(s),loss_mse on all data is0.0224109
After 26000 training step(s),loss_mse on all data is0.0224109
After 26500 training step(s),loss_mse on all data is0.0224109
After 27000 training step(s),loss_mse on all data is0.0224109
After 27500 training step(s),loss_mse on all data is0.0224109
After 28000 training step(s),loss_mse on all data is0.0224109
After 28500 training step(s),loss_mse on all data is0.0224109
After 29000 training step(s),loss_mse on all data is0.0224109
After 29500 training step(s),loss_mse on all data is0.0224109
正态分布随机数 搭配 adam优化器
After 0 training step(s),loss_mse on all data is24.8103
After 500 training step(s),loss_mse on all data is3.68355
After 1000 training step(s),loss_mse on all data is1.09463
After 1500 training step(s),loss_mse on all data is0.337334
After 2000 training step(s),loss_mse on all data is0.0700731
After 2500 training step(s),loss_mse on all data is0.0251817
After 3000 training step(s),loss_mse on all data is0.0224632
After 3500 training step(s),loss_mse on all data is0.0224112
After 4000 training step(s),loss_mse on all data is0.0224109
After 4500 training step(s),loss_mse on all data is0.0224109
After 5000 training step(s),loss_mse on all data is0.0224109
After 5500 training step(s),loss_mse on all data is0.0224109
After 6000 training step(s),loss_mse on all data is0.0224109
After 6500 training step(s),loss_mse on all data is0.0224109
After 7000 training step(s),loss_mse on all data is0.0224109
After 7500 training step(s),loss_mse on all data is0.0224109
After 8000 training step(s),loss_mse on all data is0.0224109
After 8500 training step(s),loss_mse on all data is0.0224109
After 9000 training step(s),loss_mse on all data is0.0224109
After 9500 training step(s),loss_mse on all data is0.0224109
After 10000 training step(s),loss_mse on all data is0.0224109
After 10500 training step(s),loss_mse on all data is0.0224109
After 11000 training step(s),loss_mse on all data is0.0224109
After 11500 training step(s),loss_mse on all data is0.0224109
After 12000 training step(s),loss_mse on all data is0.0224109
After 12500 training step(s),loss_mse on all data is0.0224109
After 13000 training step(s),loss_mse on all data is0.0224109
After 13500 training step(s),loss_mse on all data is0.0224109
After 14000 training step(s),loss_mse on all data is0.0224109
After 14500 training step(s),loss_mse on all data is0.0224109
After 15000 training step(s),loss_mse on all data is0.0224109
After 15500 training step(s),loss_mse on all data is0.0224109
After 16000 training step(s),loss_mse on all data is0.0224109
After 16500 training step(s),loss_mse on all data is0.0224109
After 17000 training step(s),loss_mse on all data is0.0224109
After 17500 training step(s),loss_mse on all data is0.0224109
After 18000 training step(s),loss_mse on all data is0.0224109
After 18500 training step(s),loss_mse on all data is0.0224109
After 19000 training step(s),loss_mse on all data is0.0224109
After 19500 training step(s),loss_mse on all data is0.0224109
After 20000 training step(s),loss_mse on all data is0.0224109
After 20500 training step(s),loss_mse on all data is0.0224109
After 21000 training step(s),loss_mse on all data is0.0224109
After 21500 training step(s),loss_mse on all data is0.0224109
After 22000 training step(s),loss_mse on all data is0.0224109
After 22500 training step(s),loss_mse on all data is0.0224109
After 23000 training step(s),loss_mse on all data is0.0224109
After 23500 training step(s),loss_mse on all data is0.0224109
After 24000 training step(s),loss_mse on all data is0.0224109
After 24500 training step(s),loss_mse on all data is0.0224109
After 25000 training step(s),loss_mse on all data is0.0224109
After 25500 training step(s),loss_mse on all data is0.0224109
After 26000 training step(s),loss_mse on all data is0.0224109
After 26500 training step(s),loss_mse on all data is0.0224109
After 27000 training step(s),loss_mse on all data is0.0224109
After 27500 training step(s),loss_mse on all data is0.0224109
After 28000 training step(s),loss_mse on all data is0.0224109
After 28500 training step(s),loss_mse on all data is0.0224109
After 29000 training step(s),loss_mse on all data is0.0224109
After 29500 training step(s),loss_mse on all data is0.0224109
去掉偏离过大的正态分布 搭配 momentum优化器
After 0 training step(s),loss_mse on all data is1.20265
After 500 training step(s),loss_mse on all data is0.0232303
After 1000 training step(s),loss_mse on all data is0.0224182
After 1500 training step(s),loss_mse on all data is0.022411
After 2000 training step(s),loss_mse on all data is0.0224109
After 2500 training step(s),loss_mse on all data is0.0224109
After 3000 training step(s),loss_mse on all data is0.0224109
After 3500 training step(s),loss_mse on all data is0.0224109
After 4000 training step(s),loss_mse on all data is0.0224109
After 4500 training step(s),loss_mse on all data is0.0224109
After 5000 training step(s),loss_mse on all data is0.0224109
After 5500 training step(s),loss_mse on all data is0.0224109
After 6000 training step(s),loss_mse on all data is0.0224109
After 6500 training step(s),loss_mse on all data is0.0224109
After 7000 training step(s),loss_mse on all data is0.0224109
After 7500 training step(s),loss_mse on all data is0.0224109
After 8000 training step(s),loss_mse on all data is0.0224109
After 8500 training step(s),loss_mse on all data is0.0224109
After 9000 training step(s),loss_mse on all data is0.0224109
After 9500 training step(s),loss_mse on all data is0.0224109
After 10000 training step(s),loss_mse on all data is0.0224109
After 10500 training step(s),loss_mse on all data is0.0224109
After 11000 training step(s),loss_mse on all data is0.0224109
After 11500 training step(s),loss_mse on all data is0.0224109
After 12000 training step(s),loss_mse on all data is0.0224109
After 12500 training step(s),loss_mse on all data is0.0224109
After 13000 training step(s),loss_mse on all data is0.0224109
After 13500 training step(s),loss_mse on all data is0.0224109
After 14000 training step(s),loss_mse on all data is0.0224109
After 14500 training step(s),loss_mse on all data is0.0224109
After 15000 training step(s),loss_mse on all data is0.0224109
After 15500 training step(s),loss_mse on all data is0.0224109
After 16000 training step(s),loss_mse on all data is0.0224109
After 16500 training step(s),loss_mse on all data is0.0224109
After 17000 training step(s),loss_mse on all data is0.0224109
After 17500 training step(s),loss_mse on all data is0.0224109
After 18000 training step(s),loss_mse on all data is0.0224109
After 18500 training step(s),loss_mse on all data is0.0224109
After 19000 training step(s),loss_mse on all data is0.0224109
After 19500 training step(s),loss_mse on all data is0.0224109
After 20000 training step(s),loss_mse on all data is0.0224109
After 20500 training step(s),loss_mse on all data is0.0224109
After 21000 training step(s),loss_mse on all data is0.0224109
After 21500 training step(s),loss_mse on all data is0.0224109
After 22000 training step(s),loss_mse on all data is0.0224109
After 22500 training step(s),loss_mse on all data is0.0224109
After 23000 training step(s),loss_mse on all data is0.0224109
After 23500 training step(s),loss_mse on all data is0.0224109
After 24000 training step(s),loss_mse on all data is0.0224109
After 24500 training step(s),loss_mse on all data is0.0224109
After 25000 training step(s),loss_mse on all data is0.0224109
After 25500 training step(s),loss_mse on all data is0.0224109
After 26000 training step(s),loss_mse on all data is0.0224109
After 26500 training step(s),loss_mse on all data is0.0224109
After 27000 training step(s),loss_mse on all data is0.0224109
After 27500 training step(s),loss_mse on all data is0.0224109
After 28000 training step(s),loss_mse on all data is0.0224109
After 28500 training step(s),loss_mse on all data is0.0224109
After 29000 training step(s),loss_mse on all data is0.0224109
After 29500 training step(s),loss_mse on all data is0.0224109
从均匀分布[0,1)中采样 搭配 momentum优化器
After 0 training step(s),loss_mse on all data is0.71336
After 500 training step(s),loss_mse on all data is0.0253618
After 1000 training step(s),loss_mse on all data is0.0228901
After 1500 training step(s),loss_mse on all data is0.0224956
After 2000 training step(s),loss_mse on all data is0.0224263
After 2500 training step(s),loss_mse on all data is0.0224138
After 3000 training step(s),loss_mse on all data is0.0224114
After 3500 training step(s),loss_mse on all data is0.022411
After 4000 training step(s),loss_mse on all data is0.0224109
After 4500 training step(s),loss_mse on all data is0.0224109
After 5000 training step(s),loss_mse on all data is0.0224109
After 5500 training step(s),loss_mse on all data is0.0224109
After 6000 training step(s),loss_mse on all data is0.0224109
After 6500 training step(s),loss_mse on all data is0.0224109
After 7000 training step(s),loss_mse on all data is0.0224109
After 7500 training step(s),loss_mse on all data is0.0224109
After 8000 training step(s),loss_mse on all data is0.0224109
After 8500 training step(s),loss_mse on all data is0.0224109
After 9000 training step(s),loss_mse on all data is0.0224109
After 9500 training step(s),loss_mse on all data is0.0224109
After 10000 training step(s),loss_mse on all data is0.0224109
After 10500 training step(s),loss_mse on all data is0.0224109
After 11000 training step(s),loss_mse on all data is0.0224109
After 11500 training step(s),loss_mse on all data is0.0224109
After 12000 training step(s),loss_mse on all data is0.0224109
After 12500 training step(s),loss_mse on all data is0.0224109
After 13000 training step(s),loss_mse on all data is0.0224109
After 13500 training step(s),loss_mse on all data is0.0224109
After 14000 training step(s),loss_mse on all data is0.0224109
After 14500 training step(s),loss_mse on all data is0.0224109
After 15000 training step(s),loss_mse on all data is0.0224109
After 15500 training step(s),loss_mse on all data is0.0224109
After 16000 training step(s),loss_mse on all data is0.0224109
After 16500 training step(s),loss_mse on all data is0.0224109
After 17000 training step(s),loss_mse on all data is0.0224109
After 17500 training step(s),loss_mse on all data is0.0224109
After 18000 training step(s),loss_mse on all data is0.0224109
After 18500 training step(s),loss_mse on all data is0.0224109
After 19000 training step(s),loss_mse on all data is0.0224109
After 19500 training step(s),loss_mse on all data is0.0224109
After 20000 training step(s),loss_mse on all data is0.0224109
After 20500 training step(s),loss_mse on all data is0.0224109
After 21000 training step(s),loss_mse on all data is0.0224109
After 21500 training step(s),loss_mse on all data is0.0224109
After 22000 training step(s),loss_mse on all data is0.0224109
After 22500 training step(s),loss_mse on all data is0.0224109
After 23000 training step(s),loss_mse on all data is0.0224109
After 23500 training step(s),loss_mse on all data is0.0224109
After 24000 training step(s),loss_mse on all data is0.0224109
After 24500 training step(s),loss_mse on all data is0.0224109
After 25000 training step(s),loss_mse on all data is0.0224109
After 25500 training step(s),loss_mse on all data is0.0224109
After 26000 training step(s),loss_mse on all data is0.0224109
After 26500 training step(s),loss_mse on all data is0.0224109
After 27000 training step(s),loss_mse on all data is0.0224109
After 27500 training step(s),loss_mse on all data is0.0224109
After 28000 training step(s),loss_mse on all data is0.0224109
After 28500 training step(s),loss_mse on all data is0.0224109
After 29000 training step(s),loss_mse on all data is0.0224109
After 29500 training step(s),loss_mse on all data is0.0224109
实验结论
因为我个人精力有限,所以目前并没有完整将排列组合的所有可能情况做完,实在抱歉。
简单的结论如下:
此实验中,momentum优化器在所有反向传播方法中表现最好;
此实验中,“去掉偏离过大的正态分布 搭配 momentum优化器”是表现最好的一组搭配。



